Python绘制包点图(附带实例)
包点图是一种用来展示数据分布的图表类型,它使用点来表示数据点的位置和数量。
在包点图中,每个数据点都用一个小圆点或小方块来表示,通常是在一条水平或垂直的轴上进行排列。数据点的位置表示其数值,而数据点的数量则可以通过点的大小、颜色或形状来表示。
包点图通常用于展示分类数据的分布情况,特别是当数据量较少或数据点之间存在重叠时。通过将数据点以点的形式直接绘制在轴上,包点图可以清晰地展示数据的集中程度和分布形态,同时也能够直观地比较不同类别之间的差异。
包点图的优点包括简洁直观、易于理解和阅读,同时也可以有效地展示异常值和集中趋势。然而,当数据点数量较大或重叠较多时,包点图可能会变得混乱不清,此时可以考虑使用其他类型的图表来更好地展示数据。
【实例 1】利用包点图显示不同制造商的平均城市里程。输入如下 Python 代码:
接着,使用点图展示了每个制造商的平均城市里程,其中点的大小和颜色表示了城市里程的数值,同时添加了相应的标题、标签和刻度。
输出的结果如下图所示:

图 1 包点图1
【实例 2】创建一个包点图,其中点的大小和颜色都是基于 mpg_z 列的值进行设置的,并在每个点上添加 mpg_z 的值作为标签。输入如下代码:
输出的结果如下图所示:
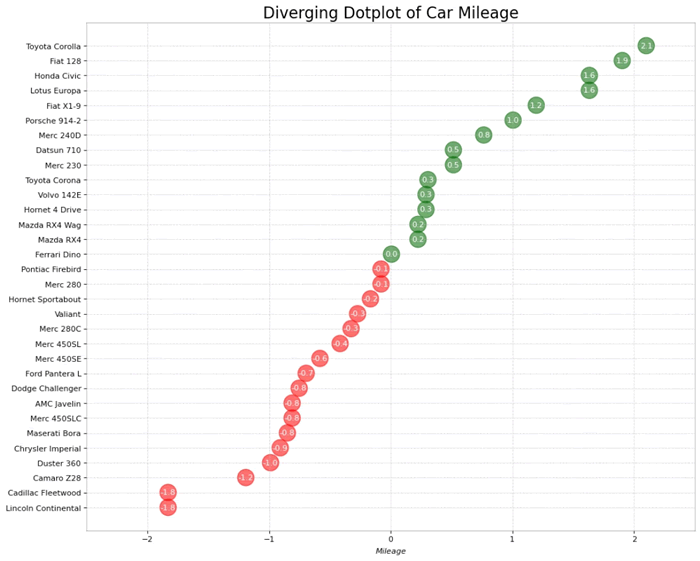
图 2 包点图2
在包点图中,每个数据点都用一个小圆点或小方块来表示,通常是在一条水平或垂直的轴上进行排列。数据点的位置表示其数值,而数据点的数量则可以通过点的大小、颜色或形状来表示。
包点图通常用于展示分类数据的分布情况,特别是当数据量较少或数据点之间存在重叠时。通过将数据点以点的形式直接绘制在轴上,包点图可以清晰地展示数据的集中程度和分布形态,同时也能够直观地比较不同类别之间的差异。
包点图的优点包括简洁直观、易于理解和阅读,同时也可以有效地展示异常值和集中趋势。然而,当数据点数量较大或重叠较多时,包点图可能会变得混乱不清,此时可以考虑使用其他类型的图表来更好地展示数据。
【实例 1】利用包点图显示不同制造商的平均城市里程。输入如下 Python 代码:
import pandas as pd
import matplotlib.pyplot as plt
df_raw=pd.read_csv("D:/DingJB/PyData/mpg_ggplot2.csv") # 读取数据
# 按制造商分组,并计算每个制造商的平均城市里程
df=df_raw[['cty','manufacturer']].groupby('manufacturer').apply(
lambda x:x.mean())
# 按城市里程排序数据
df.sort_values('cty',inplace=True)
df.reset_index(inplace=True)
fig,ax=plt.subplots(figsize=(8,5),dpi=80) # 绘图
# 使用hlines()绘制水平线条,代表每个制造商
ax.hlines(y=df.index,xmin=11,xmax=26,color='gray',alpha=0.7,
linewidth=1,linestyles='dashdot')
# 使用scatter()绘制点,点的位置表示城市里程
ax.scatter(y=df.index,x=df.cty,s=75,color='firebrick',alpha=0.7)
# 设置标题、标签、刻度和X轴范围
ax.set_title('Dot Plot for Highway Mileage', fontdict={'size':16}) # 设置标题
ax.set_xlabel('Miles Per Gallon') # 设置横轴标签
ax.set_yticks(df.index) # 设置纵轴刻度
ax.set_yticklabels(df.manufacturer.str.title(),fontdict={
'horizontalalignment':'right'}) # 设置纵轴标签
ax.set_xlim(10,27) # 设置X轴范围
plt.show()
上述代码首先从 CSV 文件中读取原始数据,并按照制造商分组,计算每个制造商的平均城市里程,并以水平线条的形式展示在图中,每个制造商对应一条水平线条。接着,使用点图展示了每个制造商的平均城市里程,其中点的大小和颜色表示了城市里程的数值,同时添加了相应的标题、标签和刻度。
输出的结果如下图所示:
图 1 包点图1
【实例 2】创建一个包点图,其中点的大小和颜色都是基于 mpg_z 列的值进行设置的,并在每个点上添加 mpg_z 的值作为标签。输入如下代码:
# 导入必要的库
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_csv("D:/DingJB/PyData/mtcars1.csv") # 读取数据
# 提取'mpg'列作为x变量,并计算其标准化值
x=df.loc[:,['mpg']]
df['mpg_z']=(x-x.mean())/x.std()
# 根据'mpg_z'列的值确定颜色
df['colors']=['red' if x<0 else 'darkgreen' for x in df['mpg_z']]
df.sort_values('mpg_z',inplace=True) # 根据'mpg_z'列的值对数据进行排序
df.reset_index(inplace=True) # 重置索引
# 绘制图形
plt.figure(figsize=(14,12),dpi=80)
plt.scatter(df.mpg_z,df.index,s=450,alpha=0.6,color=df.colors)
# 在每个点上添加'mpg_z'的值作为标签
for x,y,tex in zip(df.mpg_z,df.index,df.mpg_z):
t=plt.text(x,y,round(tex,1),
horizontalalignment='center',
verticalalignment='center',
fontdict={'color':'white'})
# 轻化边框
plt.gca().spines["top"].set_alpha(0.3)
plt.gca().spines["bottom"].set_alpha(0.3)
plt.gca()["right"].set_alpha(0.3)
plt.gca().spines["left"].set_alpha(0.3)
plt.yticks(df.index,df.cars) # 设置Y轴刻度标签
plt.title('Diverging Dotplot of Car Mileage',
fontdict={'size':20})
plt.xlabel('$Mileage$') # 设置X轴标签
plt.grid(linestyle='--',alpha=0.5) # 添加网格线
plt.xlim(-2.5,2.5) # 设置X轴范围
plt.show()
上述代码利用包点图展示了汽车里程数据的分布情况,通过计算并标准化里程值,以点的大小和颜色形式直观呈现不同汽车的里程表现,同时添加了标签显示标准化值,使得数据分布更易于理解。输出的结果如下图所示:
图 2 包点图2
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: