Python绘制散点图(非常详细,附带实例)
散点图(Scatter Plot)是一种用于可视化两个连续变量之间关系的图表类型。它以坐标系中的点的位置来表示数据的取值,并通过点的分布来展示两个变量之间的相关性、趋势和离散程度。
散点图可以展示两个变量之间的分布模式和趋势,帮助观察变量之间的关系和可能的相关性。通过散点图可以发现数据的聚集、离散、趋势、异常值等特征。
当数据点较多时,散点图可能会出现重叠,导致点的形状和分布难以辨认,此时可以使用透明度、颜色编码等方式来区分和凸显不同的数据子集。
在 Python 中构建散点图,最简单的方法是利用 Seaborn,而 Matplotlib 允许更高级别的定制。如果需要构建交互式图表,可以使用 Plotly。
输出的结果如下图所示:
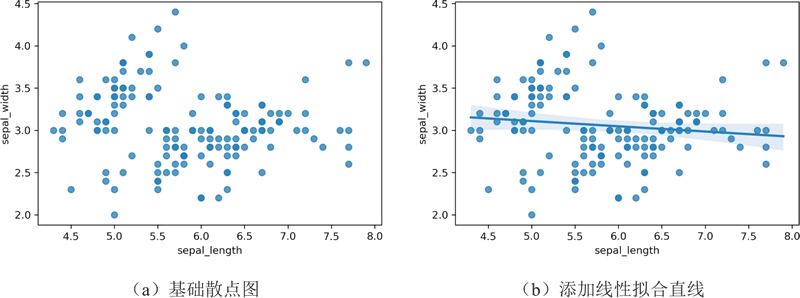
图 1 散点图1
【实例 2】利用 midwest_filter.csv 数据集绘制散点图,展示中西部地区的面积与人口之间的关系。输入如下代码:
每个类别使用不同的颜色标识,散点图的 X 轴为 area 列,Y 轴为 poptotal 列。图形修饰部分设置了 X 轴和 Y 轴的范围、标签以及刻度字体大小,并添加了图例和标题。
输出的结果如下图所示:
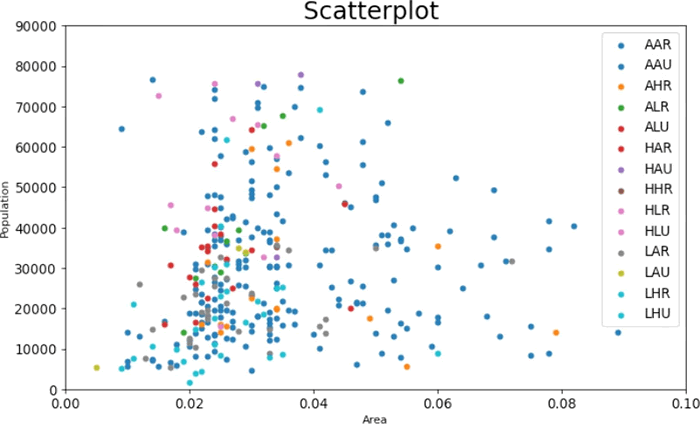
图 2 散点图2
输出的结果如下图所示:

图 3 添加线性回归线的散点图
在 Seaborn 中,通过 marker 可以控制点(标记)的形状,通过以下代码可以获取点的不同形状的符号,读者可自行尝试。
输出的结果如下图所示:
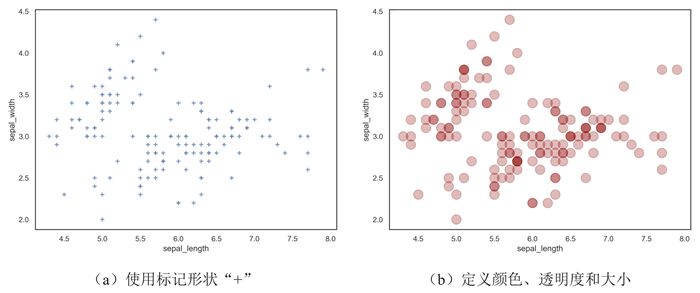
图 4 自定义点形状的散点图
【实例 5】使用 Seaborn 的 regplot() 函数在鸢尾花(iris)数据集上绘制散点图,每幅散点图均按照不同的方式(使用分类变量)对数据子集进行着色和标记。输入如下代码:
输出的结果如下图所示:
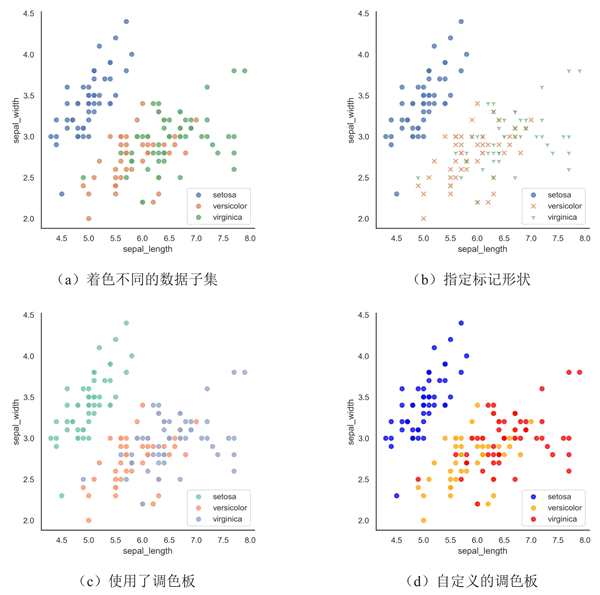
图 5 散点图
为避免这种情况,可将数据点稍微抖动,以便可以直观地看到它们。使用 Seaborn 的 stripplot() 可以很方便地实现这个功能。
【实例 6】绘制抖动散点图。输入如下代码:
图 6 抖动散点图
散点图可以展示两个变量之间的分布模式和趋势,帮助观察变量之间的关系和可能的相关性。通过散点图可以发现数据的聚集、离散、趋势、异常值等特征。
当数据点较多时,散点图可能会出现重叠,导致点的形状和分布难以辨认,此时可以使用透明度、颜色编码等方式来区分和凸显不同的数据子集。
在 Python 中构建散点图,最简单的方法是利用 Seaborn,而 Matplotlib 允许更高级别的定制。如果需要构建交互式图表,可以使用 Plotly。
Python绘制基础散点图
【实例 1】使用 Seaborn 库绘制鸢尾花(iris)数据集中萼片长度(sepal_length)与萼片宽度(sepal_width)之间的散点图。输入如下代码:
import seaborn as sns # 导入 Seaborn 库并简写为 sns
df=sns.load_dataset('iris') # 加载 iris 数据集
# 绘制散点图
sns.regplot(x=df["sepal_length"], y=df["sepal_width"])
# ① 绘制散点图(默认进行线性拟合)
sns.regplot(x=df["sepal_length"], y=df["sepal_width"], fit_reg=False)
# ② 绘制散点图(不进行线性拟合)
上述代码使用 Seaborn 库绘制了 iris 数据集中 sepal_length 和 sepal_width 两列之间的散点图,并提供了两种不同的可视化方式:
- ① 绘制默认情况不进行线性拟合的散点图,即不在图中添加拟合直线;
- ② 绘制不进行线性拟合的散点图,即只显示原始的数据点,而没有拟合直线。
输出的结果如下图所示:
图 1 散点图1
【实例 2】利用 midwest_filter.csv 数据集绘制散点图,展示中西部地区的面积与人口之间的关系。输入如下代码:
# 导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
midwest=pd.read_csv('D:/DingJB/PyData/midwest_filter.csv') # 导入数据集
categories=np.unique(midwest['category']) # 获取数据集中的唯一类别
# 生成与唯一类别数量相同的颜色
# 使用Matplotlib的颜色映射函数来生成颜色
colors=plt.cm.tab10(i/float(len(categories)-1) for i inrange(len(categories))]
# 绘制每个类别的图形
# 设置图形的大小、分辨率和背景色
plt.figure(figsize=(10,6),dpi=80,facecolor='w',edgecolor='k')
# 遍历每个类别,并使用 scatter() 函数绘制散点图
for i,category in enumerate(categories):
# 使用 loc() 方法筛选出特定类别的数据,并绘制散点图
plt.scatter('area','poptotal',
data=midwest.loc[midwest.category==category,:],
s=20,c=colors[i],label=str(category))
# 图形修饰
plt.gca().set_xlim(0.0,0.1),ylim=(0,90000)
xlabel='Area',ylabel='Population') # 设置 X 轴和 Y 轴的范围、标签
# 设置 X 轴和 Y 轴的刻度字体大小
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.title("Scatterplot ",fontsize=222) # 设置图形标题
plt.legend(fontsize=12) # 添加图例
plt.show()
上述代码从 CSV 文件中导入了数据集 midwest_filter.csv,并获取了数据集中的唯一类别,为每个类别生成颜色,并遍历每个类别,使用散点图展示了数据集中不同类别的数据。每个类别使用不同的颜色标识,散点图的 X 轴为 area 列,Y 轴为 poptotal 列。图形修饰部分设置了 X 轴和 Y 轴的范围、标签以及刻度字体大小,并添加了图例和标题。
输出的结果如下图所示:
图 2 散点图2
Python绘制自定义线性回归拟合直线
【实例 3】使用 Seaborn 的 regplot() 函数在鸢尾花(iris)数据集上绘制添加线性回归的散点图。输入如下代码:
import pandas as pd # 导入 Pandas库并简写为 pd
import matplotlib.pyplot as plt # 导入 matplotlib.pyplot 模块并简写为 plt
import seaborn as sns # 导入 Seaborn 库并简写为 sns
df=sns.load_dataset('iris') # 加载 iris 数据集
# ① 绘制散点图,并添加红色线性回归线
fig,ax=plt.subplots(figsize=(8,6)) # 创建图形和子图对象,并设置图形大小
sns.regplot(x=df["sepal_length"],y=df["sepal_width"],
line_kws={"color":"r"},ax=ax) # 绘制散点图,指定横纵轴数据
# 设置线性回归线颜色为红色
plt.show()
# ② 绘制散点图,并添加半透明的红色线性回归线
fig,ax=plt.subplots(figsize=(8,6)) # 创建图形和子图对象,并设置图形大小
sns.regplot(x=df["sepal_length"],y=df["sepal_width"],
line_kws={"color":"r","alpha":0.4},ax=ax) # 绘制散点图,指定横纵轴数据
# 设置线性回归线颜色为红色,透明度为 0.4
plt.show()
# ③ 绘制散点图,并自定义线性回归线的线宽、线型和颜色
fig,ax=plt.subplots(figsize=(8,6)) # 创建图形和子图对象,并设置图形大小
sns.regplot(x=df["sepal_length"],y=df["sepal_width"],
line_kws={"color":"r","alpha":0.4,"lw":5,"ls":"--"},ax=ax) # 设置线性回归线的颜色、透明度、线宽和线型
plt.show()
上述代码绘制了 3 个散点图,每个散点图都添加了线性回归线,并对线性回归线进行了不同的自定义设置:
- ① 绘制添加了红色线性回归线的散点图;
- ② 绘制添加了半透明的红色线性回归线的散点图;
- ③ 绘制添加了线性回归线的散点图,并对回归线的线宽、线型和颜色进行了自定义设置(红色,透明度为 0.4,线宽为 5,线型为虚线)。
输出的结果如下图所示:
图 3 添加线性回归线的散点图
在 Seaborn 中,通过 marker 可以控制点(标记)的形状,通过以下代码可以获取点的不同形状的符号,读者可自行尝试。
from matplotlib import markers print(markers.MarkerStyle.markers.keys())
Python绘制自定义点的形状
【实例 4】使用 Seaborn 的 regplot() 函数在鸢尾花(iris)数据集上绘制散点图,尝试采用不同的点形状。输入如下代码:
fig,ax=plt.subplots(figsize=(8,6)) # 创建图形和子图对象,并设置图形大小
# ① 绘制散点图,不添加回归线,标记形状为 "+"
sns.regplot(x=df["sepal_length"], y=df["sepal_width"],
marker="+",fit_reg=False,ax=ax)
plt.show()
fig,ax=plt.subplots(figsize=(8,6)) # 创建图形和子图对象,并设置图形大小
# ② 绘制散点图,不添加回归线,设置散点标记颜色为暗红色,透明度为 0.3,标记大小为 200
sns.regplot(x=df["sepal_length"], y=df["sepal_width"],fit_reg=False,
scatter_kws={"color":"darkred","alpha":0.3,"s":200},ax=ax)
plt.show()
上述代码使用 Seaborn 绘制了两个散点图,都没有添加线性回归线,并对散点的标记进行了不同的自定义设置:
- ① 使用标记形状“+”绘制散点图;
- ② 对散点的颜色、透明度和大小进行了自定义设置(暗红色,透明度为 0.3,大小为 200)。
输出的结果如下图所示:
图 4 自定义点形状的散点图
【实例 5】使用 Seaborn 的 regplot() 函数在鸢尾花(iris)数据集上绘制散点图,每幅散点图均按照不同的方式(使用分类变量)对数据子集进行着色和标记。输入如下代码:
import seaborn as sns # 导入 Seaborn 库
import matplotlib.pyplot as plt # 导入 matplotlib.pyplot 库
df=sns.load_dataset('iris') # 加载 iris 数据集
# 使用 'hue' 参数提供一个因子变量,并绘制散点图
sns.lmplot(x="sepal_length", y="sepal_width",
data=df, fit_reg=False, hue='species', legend=False)
# 将图例移动到图形中的一个空白部分
plt.legend(loc='lower right')
plt.show()
# 绘制散点图,并指定每个数据子集的标记形状
sns.lmplot(x="sepal_length", y="sepal_width", data=df,
fit_reg=False, hue='species', legend=False, markers=["o","x","|"])
# 将图例移动到图形中的一个空白部分
plt.legend(loc='lower right')
plt.show()
# 使用调色板来着色不同的数据子集
sns.lmplot(x="sepal_length", y="sepal_width",
data=df, fit_reg=False, hue='species',
legend=False, palette="Set2")
# 将图例移动到图形中的一个空白部分
plt.legend(loc='lower right')
plt.show()
# 控制每个数据子集的颜色
sns.lmplot(x="sepal_length", y="sepal_width",
data=df, fit_reg=False, hue='species', legend=False,
palette=dict(setosa="blue",virginica="red",versicolor="green"))
# 将图例移动到图形中的一个空白部分
plt.legend(loc='lower right')
plt.show()
上述代码使用 Seaborn 的 lmplot() 函数绘制了 4 个不同的散点图,每个图都根据 Iris 数据集中的不同品种进行了分组,并采用不同的方式来设置颜色和标记形状:
- 使用 'species' 列作为因子变量来着色不同的数据子集,并在图例中添加了品种信息。
- 在(1)的基础上,指定不同数据子集的标记形状为圆圈、叉和 1 代表的符号。
- 使用了调色板 Set2 来着色不同的数据子集。
- 使用自定义的调色板来控制不同数据子集的颜色,其中 'setosa' 品种为蓝色,'virginica' 品种为红色,'versicolor' 品种为绿色,并在图例中添加了相应的颜色说明。
输出的结果如下图所示:
图 5 散点图
Python绘制抖动散点图
通常多个数据点具有完全相同的 X 值和 Y 值,这样会导致多个点绘制重叠并隐藏。为避免这种情况,可将数据点稍微抖动,以便可以直观地看到它们。使用 Seaborn 的 stripplot() 可以很方便地实现这个功能。
【实例 6】绘制抖动散点图。输入如下代码:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df=pd.read_csv("D:/mpg_ggplot2.csv") # 导入数据
# 绘制 Stripplot
fig,ax=plt.subplots(figsize=(12,6),dpi=80)
sns.stripplot(x='cty',y='hwy',hue='class',data=df,jitter=0.25,size=6,
ax=ax,linewidth=.5)
# 修饰
plt.title('Use jittered plots to avoid overlapping of points',fontsize=222)
plt.show()
上述代码使用 Seaborn 库绘制了一个带有 Jitter 效果的 Stripplot 图,展示了城市里程(cty)和高速公路里程(hwy)之间的关系,并根据车辆类别(class)进行了分类显示。Jitter 效果使得数据点在 X 轴方向上稍微分散,以避免重叠。输出的结果如下图所示。图 6 抖动散点图
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: