强化学习是什么(超级详细)
机器学习研究的是计算机程序如何实现智能体通过学习提高自身处理性能的问题。计算机程序具有智能的基本标志是能够学习。
强化学习(Reinforcement Learning,RL)因为具有生物相关性和学习自主性,在机器学习领域和人工智能领域引发了极大的关注,并且在机器人控制、导弹制导、预测决策、最优控制、棋类对弈、工作调度、飞行控制、金融投资及城市交通控制等领域都有较高的实用价值。
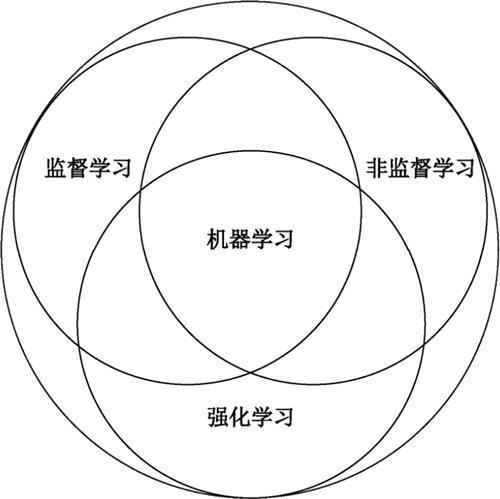
图 1 机器学习三大分支
强化学习介于监督学习和非监督学习之间,是一种试错方法,它强调基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即智能体在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。
强化学习的主要特点是智能体和环境之间不断进行交互,智能体为了获得更多的累计奖励而不断搜索和试错。
强化学习主要由 5 个部分组成,分别是智能体、环境、状态、行动和奖励,如下图所示。
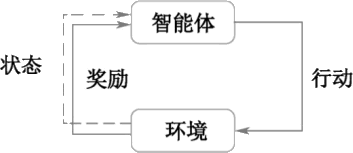
图 2 强化学习的组成
智能体指的是可以采取动作的智能个体。例如,进行棋类对弈的机器人,可以完成农药喷洒的无人机,或者在迷宫中寻找出口的机器人。
行动指的是智能体可以采取的动作的集合。一个动作当然很容易判断,但智能体是从可能的动作列表中进行选择,这个必须注意。
例如,在空中飞行的无人机,其动作列表可能包含三维空间中各种不同的速度和加速度。在电子竞技游戏中,动作列表可能包含向高处跳、向低处跳、向右跑、向左跑、下蹲、保持不动等。在股市操作中,动作列表可能包含买入、卖出、持有任何有价证券等。
环境指的是智能体行走于其中的世界。环境将智能体当前所处的状态和动作作为输入,输出的是智能体所获得的奖励和下一步的状态。
状态指的是智能体所处的具体即时状态,也就是一个具体的时间和地点,它能够将智能体和其他重要的事物关联起来,如工具、敌人或者奖励。
奖励是衡量某个智能体的行动成败的反馈。例如,在电子游戏中,当游戏人物碰到金币的时候,它就会获得奖励,遇到地雷的时候则会受到惩罚。面对任何既定的状态,智能体以动作的形式向环境输出,然后环境会返回一个新状态,这个新状态会受到基于之前状态的行动的影响和奖励。
奖励可能是即时的,也可能是迟滞的。它可以有效地评估该智能体的行动。
图 2 中的智能体指的是计算机,计算机在强化学习过程中采取行动来操纵环境,从一个状态转变到另一个状态,当它完成任务时,系统就给予它奖励,当它没完成任务时,系统就不给予奖励,这就是强化学习的核心思想。
强化学习的发展历程如下图所示。
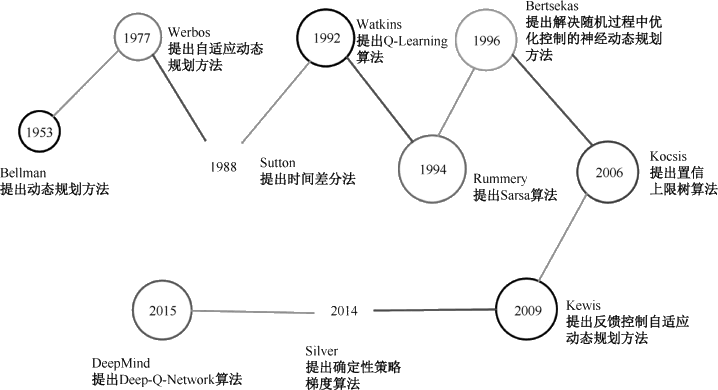
图 3 强化学习的发展历程
强化学习可以分为两大类,一类是有模型的强化学习,另一类是无模型的强化学习。有模型的强化学习有动态规划法,无模型的强化学习有蒙特卡洛法和时间差分法,如下图所示。
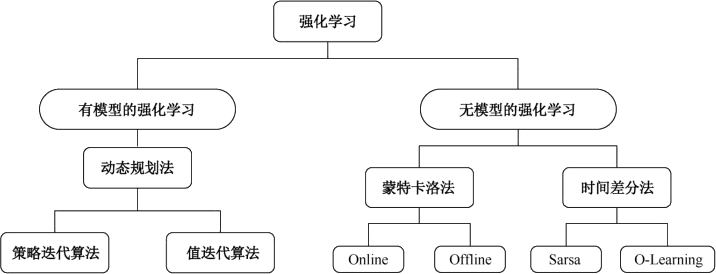
图 4 强化学习的分类
动态规划法是实现决策过程最优化的数学方法,其主要思想是求问题的最优解,求解的大问题可以分解成小问题,分解后的小问题存在最优解,将小问题的最优解组合起来就能够得到大问题的最优解。分析思路是从上往下分析问题,从下往上求解问题。
蒙特卡洛法也称统计模拟法、统计试验法,其主要思想是首先根据实际问题构造概率统计模型,问题的解恰好是求解模型的参数或数字特征;然后对模型进行抽样试验,给出所求解的近似值;最后统计处理模拟结果,给出问题解的统计估计值和精度估计值。
时间差分法是强化学习理论中最核心的内容,也是强化学习领域最重要的成果。时间差分法结合了动态规划法和蒙特卡洛法的思想,它与后两者的主要不同点在值函数估计上。
时间差分法分为两类,一类是在线控制(On-policy Learning),即一直使用一个策略来更新价值函数和选择新的动作,其代表是 Sarsa 算法。而另一类是离线控制(Off-policy Learning),即使用两个控制策略,一个策略用于选择新的动作,另一个策略用于更新价值函数,其代表是 Q-Learning 算法。
强化学习的主要特点如下:
强化学习的应用如下图所示。
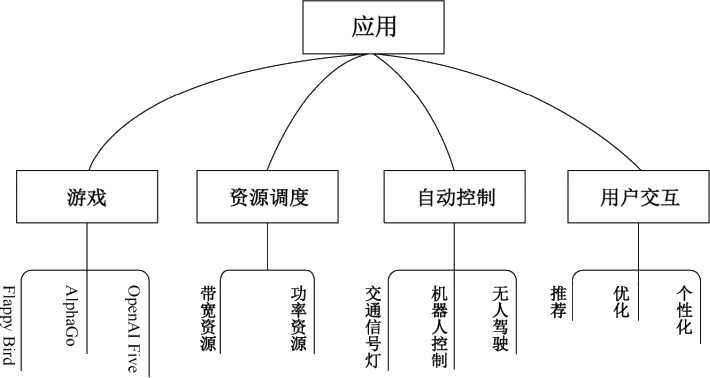
图 5 强化学习的应用
强化学习(Reinforcement Learning,RL)因为具有生物相关性和学习自主性,在机器学习领域和人工智能领域引发了极大的关注,并且在机器人控制、导弹制导、预测决策、最优控制、棋类对弈、工作调度、飞行控制、金融投资及城市交通控制等领域都有较高的实用价值。
强化学习的概念
强化学习又称增强学习、加强学习、再励学习或激励学习,是一种从环境状态到行为映射的学习,是机器学习的分支之一,如下图所示。图 1 机器学习三大分支
强化学习介于监督学习和非监督学习之间,是一种试错方法,它强调基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即智能体在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。
强化学习的主要特点是智能体和环境之间不断进行交互,智能体为了获得更多的累计奖励而不断搜索和试错。
强化学习主要由 5 个部分组成,分别是智能体、环境、状态、行动和奖励,如下图所示。
图 2 强化学习的组成
智能体指的是可以采取动作的智能个体。例如,进行棋类对弈的机器人,可以完成农药喷洒的无人机,或者在迷宫中寻找出口的机器人。
行动指的是智能体可以采取的动作的集合。一个动作当然很容易判断,但智能体是从可能的动作列表中进行选择,这个必须注意。
例如,在空中飞行的无人机,其动作列表可能包含三维空间中各种不同的速度和加速度。在电子竞技游戏中,动作列表可能包含向高处跳、向低处跳、向右跑、向左跑、下蹲、保持不动等。在股市操作中,动作列表可能包含买入、卖出、持有任何有价证券等。
环境指的是智能体行走于其中的世界。环境将智能体当前所处的状态和动作作为输入,输出的是智能体所获得的奖励和下一步的状态。
状态指的是智能体所处的具体即时状态,也就是一个具体的时间和地点,它能够将智能体和其他重要的事物关联起来,如工具、敌人或者奖励。
奖励是衡量某个智能体的行动成败的反馈。例如,在电子游戏中,当游戏人物碰到金币的时候,它就会获得奖励,遇到地雷的时候则会受到惩罚。面对任何既定的状态,智能体以动作的形式向环境输出,然后环境会返回一个新状态,这个新状态会受到基于之前状态的行动的影响和奖励。
奖励可能是即时的,也可能是迟滞的。它可以有效地评估该智能体的行动。
图 2 中的智能体指的是计算机,计算机在强化学习过程中采取行动来操纵环境,从一个状态转变到另一个状态,当它完成任务时,系统就给予它奖励,当它没完成任务时,系统就不给予奖励,这就是强化学习的核心思想。
强化学习的发展历程如下图所示。
图 3 强化学习的发展历程
强化学习的分类
强化学习可以分为两大类,一类是有模型的强化学习,另一类是无模型的强化学习。有模型的强化学习有动态规划法,无模型的强化学习有蒙特卡洛法和时间差分法,如下图所示。
图 4 强化学习的分类
动态规划法是实现决策过程最优化的数学方法,其主要思想是求问题的最优解,求解的大问题可以分解成小问题,分解后的小问题存在最优解,将小问题的最优解组合起来就能够得到大问题的最优解。分析思路是从上往下分析问题,从下往上求解问题。
蒙特卡洛法也称统计模拟法、统计试验法,其主要思想是首先根据实际问题构造概率统计模型,问题的解恰好是求解模型的参数或数字特征;然后对模型进行抽样试验,给出所求解的近似值;最后统计处理模拟结果,给出问题解的统计估计值和精度估计值。
时间差分法是强化学习理论中最核心的内容,也是强化学习领域最重要的成果。时间差分法结合了动态规划法和蒙特卡洛法的思想,它与后两者的主要不同点在值函数估计上。
时间差分法分为两类,一类是在线控制(On-policy Learning),即一直使用一个策略来更新价值函数和选择新的动作,其代表是 Sarsa 算法。而另一类是离线控制(Off-policy Learning),即使用两个控制策略,一个策略用于选择新的动作,另一个策略用于更新价值函数,其代表是 Q-Learning 算法。
强化学习的特点及应用
强化学习与监督学习、非监督学习的区别如下表所示。| 项 目 | 监督学习 | 非监督学习 | 强化学习 |
|---|---|---|---|
| 学习依据 | 基于监督信息 | 基于数据结构的假设 | 基于评估 |
| 数据来源 | 一次性给定 | 一次性给定 | 在交互中产生 |
| 决策过程 | 单步 | 无 | 序列 |
| 学习目标 | 样本到语义标签的映射 | 同一类数据的分布模式 | 选择能够获得最大奖励的状态到动作的映射 |
强化学习的主要特点如下:
- 基于评估:强化学习利用环境评估当前策略,以此为依据进行优化。
- 交互性:强化学习的数据在与环境的交互中产生。
- 序列决策过程:智能体在与环境的交互中需要做出一系列决策,这些决策往往是前后关联的。
强化学习的应用如下图所示。
图 5 强化学习的应用
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: