C语言#include的用法(非常详细,图文并茂)
在 C语言中,预处理指令 #include 对我们来说已经相当熟悉。从第一个输出 "Hello World" 的代码开始,预处理指令 #include 几乎出现在每一段代码中。
本节我们将深入探讨,为什么需要 #include 指令?#include 指令有哪些使用方式?
C语言的预处理指令 #include 用于在程序中包含其他文件的内容。这个指令可以将其他头文件(header file)中定义的函数、变量和其他符号引入当前程序中,从而扩展当前程序的功能并使用其他库中的功能。
因此,预处理指令 #include 会将文件 stdio.h 中的代码复制到该预处理指令出现处,并删除该预处理指令。
我们暂且假设文件 stdio.h 包含了函数 printf() 的定义。那么,经过预处理后,源文件 main.c 的源代码将变成以下代码:
经过预处理后,编译器使用修改后的代码进行编译。编译器首先会读取函数 printf() 的定义。因此,在其后的 main() 函数中调用 printf() 函数可以通过编译。
#include 指令的基本语法格式有两种,分别为:
对于 stdio.h 文件来说,它是编译器自带的文件,在编译器的包含目录中,因此使用尖括号即可找到该文件。对于双引号的使用场景,我们将在下面的示例中进行说明。
我们的重点是了解如何使用 #include 指令,而非如何完全模拟 printf() 函数。因此,我们的 print() 函数不需要实现得过于复杂。
在 Visual Studio 中,我们新建一个源文件,将文件名改为 print.c,并在源文件中编写如下代码:
接下来,我们在源文件 main.c 中引用 print.c 文件,并使用 print() 函数:
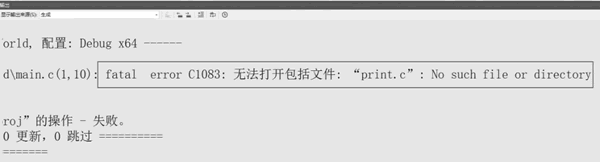
图 1 无法打开包括文件 print.c
这是因为使用尖括号形式的 #include 指令只会在编译器的包含目录中搜索文件,而编译器的包含目录中并没有 "print.c" 文件。
为了解决这个问题,我们需要扩大搜索范围,这可以通过使用双引号形式的 #include 指令来实现。#include 指令将首先在当前目录中搜索文件,若未找到,则继续搜索编译器的包含目录中是否存在该文件。
因此,我们需要修改代码,将尖括号形式更改为双引号形式:
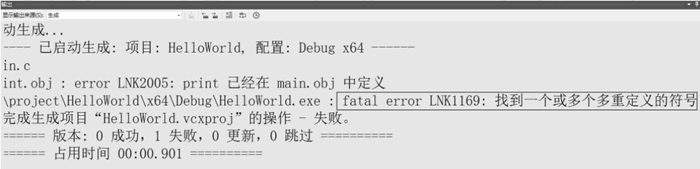
图 2 重定义了print函数
为何会出现链接错误呢?要深入了解这个问题,我们需要了解从代码到可执行文件的构建过程。
查看下图,对于每个源文件来说,编译器是独立编译的,并生成对应的目标文件:
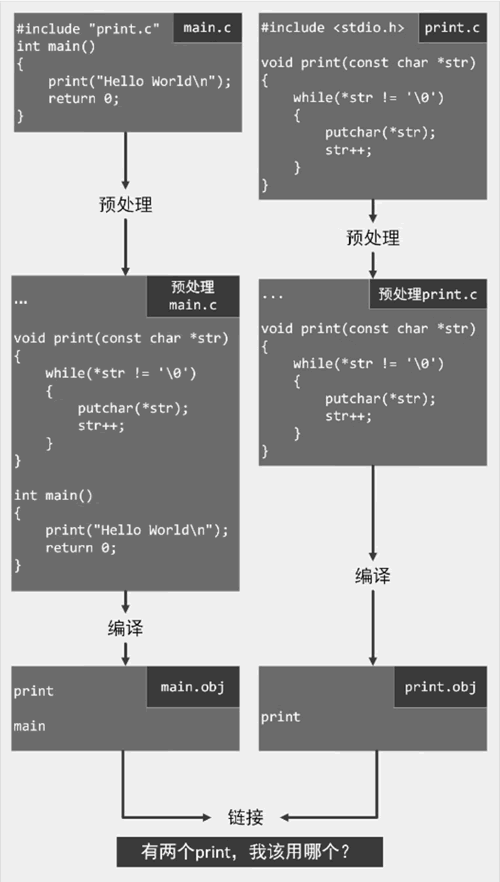
图 3 构建流程1
为了正确编译源文件 main.c,我们需要包含 print.c 文件,以便先定义 print() 函数,再使用它。目标文件 main.obj 中有一个 print() 函数,而 print.obj 文件中也有一个 print() 函数。在链接时,出现了同名函数的现象,因此链接失败。
那么,我们应该如何解决这个问题呢?关键在于编译器会分别编译每个源文件。在编译源文件 main.c 时,编译器无法识别 print 标识符具体代表什么。除了函数定义可以让编译器正确识别 print 标识符,函数声明也可以起到相同的作用。
我们将暂时从源文件 main.c 中删除 #include 指令,并将其替换为函数 print() 的声明:
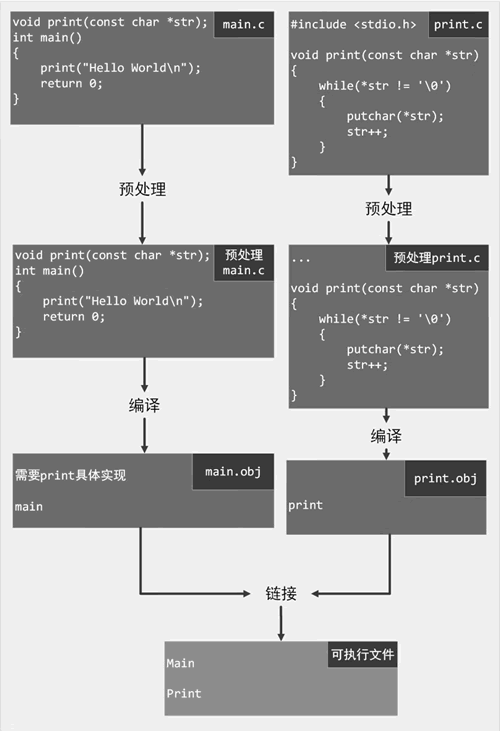
图 4 构建流程2
在编译源文件 main.c 时,编译器尽管不知道 print() 函数的具体实现细节,但知道这是一个函数,并且了解其接收的参数类型,因此编译可以继续进行。在编译生成的目标文件 main.obj 中,该目标文件指明需要 print() 函数的实现。
在链接过程中,目标文件 main.obj 表示需要 print() 函数的具体实现,而 print.obj 中恰好包含该函数的具体实现。这样,它们就可以被链接为一个可执行文件。
我们故意尝试删除文件 print.c 中的代码,看看会发生什么。查看下图,在链接过程中同样出现了错误。
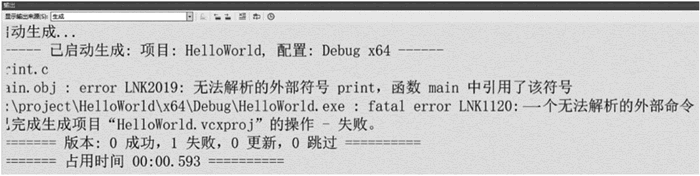
图 5 无法解析的外部符号
查看下图,main.obj 文件中的 main 函数需要 print() 函数的具体实现,而现在无法提供 print() 函数的实现,因此出现链接错误。
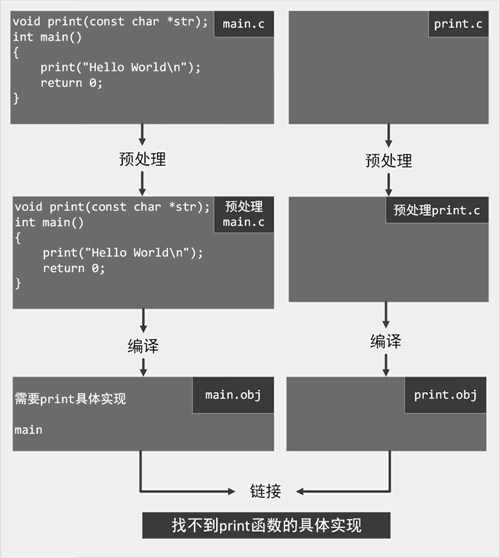
图 6 构建流程3
现在我们恢复代码,继续往下讨论。
目前,print.c 文件中仅定义了一个函数。如果 print.c 文件中定义了多个函数,在其他文件中需要使用这些函数时,就需要重复声明这些函数。
例如,如果 print.c 文件中定义了 N 个函数:
那么,我们可以把这些声明单独写在一个文件里,哪个文件需要使用这些函数,就包含这个文件。此外,这种文件不需要经过编译器编译,仅供其他文件包含。具有这种性质的文件被称作头文件,与需要被编译器编译的文件不同,其后缀名为 .h。
查看下图,要创建头文件,可以在 Visual Studio 中右击“头文件”,选择“添加”,再选择“新建项”。
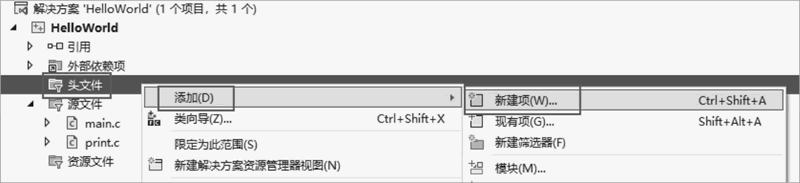
图 7 新建项
查看下图,新建一个头文件。由于它是源文件 print.c 对应的头文件,因此我们将这个头文件命名为 print.h。
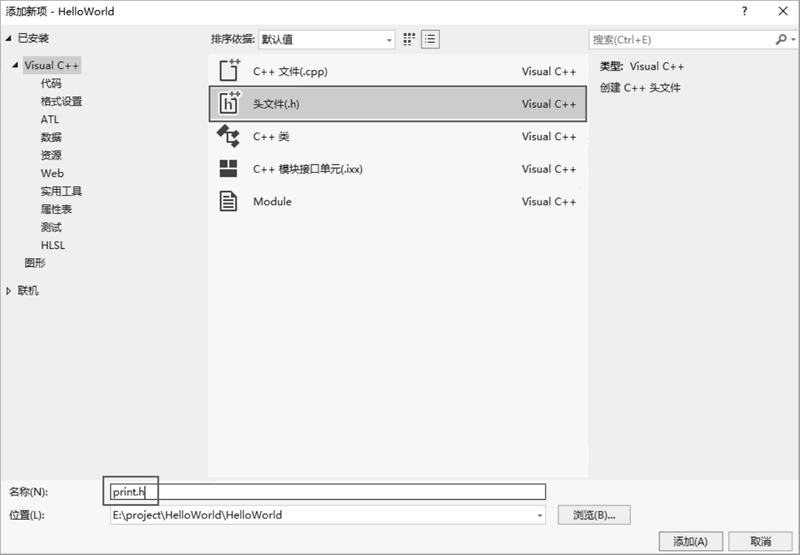
图 8 新建头文件
接着,我们将函数 print() 的声明写入 print.h 头文件中:
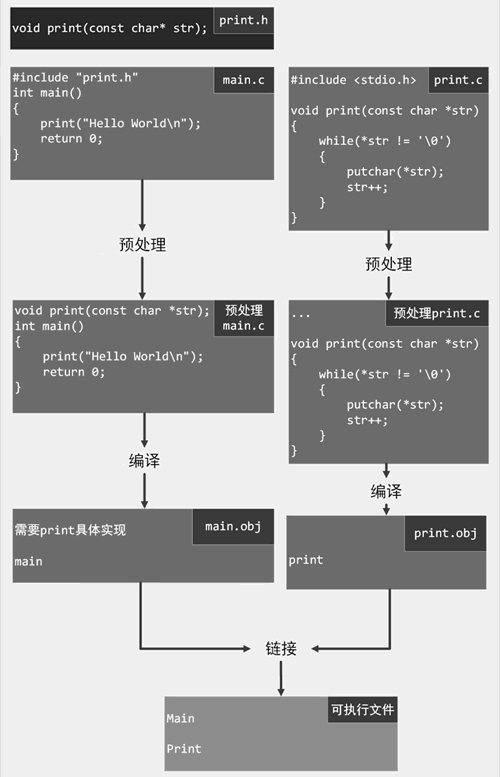
图 9 构建流程4
本节我们将深入探讨,为什么需要 #include 指令?#include 指令有哪些使用方式?
C语言#include的用法
下面实例展示了我们最熟悉的输出 "Hello World" 的代码,我们假设该代码保存在源文件 main.c 中:
#include <stdio.h>
int main()
{
printf("Hello World\n");
return 0;
}
当编译器从上至下编译源文件 main.c 时,编译器需要首先知道标识符 printf 是一个函数。接着在后面的代码中,我们可以将标识符 printf 作为函数来使用。编译器识别 printf 最常用的方式是使用预编译指令 #include <stdio.h>。C语言的预处理指令 #include 用于在程序中包含其他文件的内容。这个指令可以将其他头文件(header file)中定义的函数、变量和其他符号引入当前程序中,从而扩展当前程序的功能并使用其他库中的功能。
因此,预处理指令 #include 会将文件 stdio.h 中的代码复制到该预处理指令出现处,并删除该预处理指令。
我们暂且假设文件 stdio.h 包含了函数 printf() 的定义。那么,经过预处理后,源文件 main.c 的源代码将变成以下代码:
int printf (const char *__format, ...)
{
...
//具体实现
...
}
int main()
{
printf("Hello World\n");
return 0;
}
修改后的代码将另存为中间文件或直接输入编译器中,并不会保存到源文件中。所以,预处理器不会改动你的源文件。经过预处理后,编译器使用修改后的代码进行编译。编译器首先会读取函数 printf() 的定义。因此,在其后的 main() 函数中调用 printf() 函数可以通过编译。
#include 指令的基本语法格式有两种,分别为:
#include <头文件名> #include "头文件名"#include 指令可以用两种方式引用头文件:
-
一种是使用尖括号
<>,这种方式告诉编译器在系统路径中查找指定的头文件; -
另一种是使用双引号
" ",这种方式告诉编译器在当前目录中查找指定的头文件,如果找不到,则在系统路径中查找指定的头文件。
对于 stdio.h 文件来说,它是编译器自带的文件,在编译器的包含目录中,因此使用尖括号即可找到该文件。对于双引号的使用场景,我们将在下面的示例中进行说明。
C语言#include在多文件编程中的应用
现在,我们将模仿 printf() 的形式,编写一个简化版的 print() 函数,并使其通过 #include 来引用。我们的重点是了解如何使用 #include 指令,而非如何完全模拟 printf() 函数。因此,我们的 print() 函数不需要实现得过于复杂。
在 Visual Studio 中,我们新建一个源文件,将文件名改为 print.c,并在源文件中编写如下代码:
#include <stdio.h>
void print(const char *str)
{
while(*str != '\0')
{
putchar(*str);
str++;
}
}
接下来,我们在源文件 main.c 中引用 print.c 文件,并使用 print() 函数:
#include <print.c>
int main()
{
print("Hello World\n");
return 0;
}
当我们尝试编译代码时,出现了一个编译错误(见下图),告知我们无法打开包括文件 print.c。图 1 无法打开包括文件 print.c
这是因为使用尖括号形式的 #include 指令只会在编译器的包含目录中搜索文件,而编译器的包含目录中并没有 "print.c" 文件。
为了解决这个问题,我们需要扩大搜索范围,这可以通过使用双引号形式的 #include 指令来实现。#include 指令将首先在当前目录中搜索文件,若未找到,则继续搜索编译器的包含目录中是否存在该文件。
因此,我们需要修改代码,将尖括号形式更改为双引号形式:
#include "print.c" // 更改为双引号形式的#include指令
int main()
{
print("Hello World\n");
return 0;
}
查看下图,在尝试编译之后,我们发现出现了一个新的问题,这是一个链接错误:重定义了 print() 函数。图 2 重定义了print函数
为何会出现链接错误呢?要深入了解这个问题,我们需要了解从代码到可执行文件的构建过程。
- 预处理:执行预处理指令,修改源代码。
- 编译:将预处理后的源代码转换为二进制目标文件。
- 链接:将需要用到的目标文件合并为可执行文件。
查看下图,对于每个源文件来说,编译器是独立编译的,并生成对应的目标文件:
图 3 构建流程1
- 源文件 main.c 经过编译后,生成目标文件 main.obj;
- print.c 文件经过编译后,生成目标文件 print.obj;
- 编译完成后,链接器会启动并将所有需要的目标文件中的代码链接为一个可执行文件。
为了正确编译源文件 main.c,我们需要包含 print.c 文件,以便先定义 print() 函数,再使用它。目标文件 main.obj 中有一个 print() 函数,而 print.obj 文件中也有一个 print() 函数。在链接时,出现了同名函数的现象,因此链接失败。
那么,我们应该如何解决这个问题呢?关键在于编译器会分别编译每个源文件。在编译源文件 main.c 时,编译器无法识别 print 标识符具体代表什么。除了函数定义可以让编译器正确识别 print 标识符,函数声明也可以起到相同的作用。
我们将暂时从源文件 main.c 中删除 #include 指令,并将其替换为函数 print() 的声明:
void print(const char *str);
int main()
{
print("Hello World\n");
return 0;
}
查看下图:图 4 构建流程2
在编译源文件 main.c 时,编译器尽管不知道 print() 函数的具体实现细节,但知道这是一个函数,并且了解其接收的参数类型,因此编译可以继续进行。在编译生成的目标文件 main.obj 中,该目标文件指明需要 print() 函数的实现。
在链接过程中,目标文件 main.obj 表示需要 print() 函数的具体实现,而 print.obj 中恰好包含该函数的具体实现。这样,它们就可以被链接为一个可执行文件。
我们故意尝试删除文件 print.c 中的代码,看看会发生什么。查看下图,在链接过程中同样出现了错误。
图 5 无法解析的外部符号
查看下图,main.obj 文件中的 main 函数需要 print() 函数的具体实现,而现在无法提供 print() 函数的实现,因此出现链接错误。
图 6 构建流程3
现在我们恢复代码,继续往下讨论。
目前,print.c 文件中仅定义了一个函数。如果 print.c 文件中定义了多个函数,在其他文件中需要使用这些函数时,就需要重复声明这些函数。
例如,如果 print.c 文件中定义了 N 个函数:
void print1(const char *str); void print2(const char *str); void print3(const char *str); void print4(const char *str); void print5(const char *str); ... void printN(const char *str);那么在 main.c 源文件中需要使用这些函数时,就需要在 main.c 源文件中声明这些函数。
那么,我们可以把这些声明单独写在一个文件里,哪个文件需要使用这些函数,就包含这个文件。此外,这种文件不需要经过编译器编译,仅供其他文件包含。具有这种性质的文件被称作头文件,与需要被编译器编译的文件不同,其后缀名为 .h。
查看下图,要创建头文件,可以在 Visual Studio 中右击“头文件”,选择“添加”,再选择“新建项”。
图 7 新建项
查看下图,新建一个头文件。由于它是源文件 print.c 对应的头文件,因此我们将这个头文件命名为 print.h。
图 8 新建头文件
接着,我们将函数 print() 的声明写入 print.h 头文件中:
void print(const char* str);最后,我们将 main.c 源文件中的函数声明改为包含头文件 print.h:
#include "print.h"
int main()
{
print("Hello World\n");
return 0;
}
查看下图,函数 print() 的使用方式类似于函数 printf()。在 main.c 源文件中仅需要包含头文件就可以使用该函数。图 9 构建流程4
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: