什么是数据可视化
在介绍数据可视化之前,我们有必要对“数据科学”进行简单的介绍,这样才能站在更高的角度来理解可视化与数据科学其余各部分之间的关系。
网络爬虫、数据分析、数据可视化、机器学习等,在平常的学习或工作中,我们或多或少都听过这些名词。其实,这些名词本身就属于数据科学概念的一部分,它们背后其实是有深层联系的。
大家可能都知道,如果想从数据中提炼有用的信息,一般流程是:获取数据 -> 处理数据 -> 展示数据。网络爬虫用于获取数据,数据分析用于处理数据,数据可视化用于展示数据。而机器学习则用于进一步对数据进行建模,以便对未来的一些东西进行预测。
所谓数据科学,用简单的一句话来说就是“处理数据的科学”。对于数据科学来说,它的工作流可以总结成“OSEMN”,如下表和图片所示。
图 1 数据科学工作流
比如想要查看某个城市一天的气温变化,仅仅通过查看数据,并不容易看出其中的变化趋势。如果把数据以折线图的方式展示出来,趋势就会变得非常直观,如下图所示。
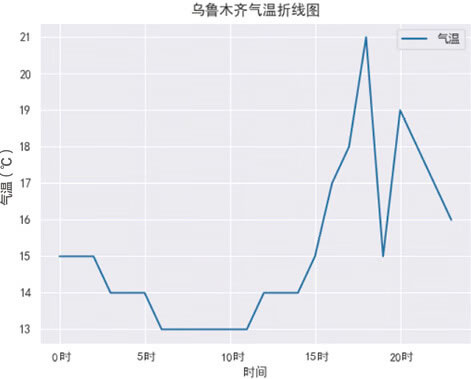
图 2 乌鲁木齐气温变化折线图
所谓数据可视化,指的就是将数据以图表的方式展示处理。
网络爬虫、数据分析、数据可视化、机器学习等,在平常的学习或工作中,我们或多或少都听过这些名词。其实,这些名词本身就属于数据科学概念的一部分,它们背后其实是有深层联系的。
大家可能都知道,如果想从数据中提炼有用的信息,一般流程是:获取数据 -> 处理数据 -> 展示数据。网络爬虫用于获取数据,数据分析用于处理数据,数据可视化用于展示数据。而机器学习则用于进一步对数据进行建模,以便对未来的一些东西进行预测。
所谓数据科学,用简单的一句话来说就是“处理数据的科学”。对于数据科学来说,它的工作流可以总结成“OSEMN”,如下表和图片所示。
| 步骤 | 常用库(Python方向) |
| Obtain(获取) | Scrapy |
| Scrub(清洗) | NumPy、pandas |
| Explore(展示) | Matplotlib、Seaborn |
| Model(建模) | scikit-learn、SciPy、TensorFlow |
| iNterpret(解析) | Bokeh、D3.js |
图 1 数据科学工作流
数据可视化是什么
数据可视化,也就是数据科学中的“Explore”(展示)这一环节。对于数据来说,我们仅从它本身很难看出背后有什么规律。如果将数据以图表的方式来展示,就可以明确地发现很多有用的信息。比如想要查看某个城市一天的气温变化,仅仅通过查看数据,并不容易看出其中的变化趋势。如果把数据以折线图的方式展示出来,趋势就会变得非常直观,如下图所示。
图 2 乌鲁木齐气温变化折线图
所谓数据可视化,指的就是将数据以图表的方式展示处理。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: