Python爬虫入门教程(非常详细)
通俗来讲,网络爬虫就是一段程序,可以在网站上获取需要的信息,如文字、视频、图片等。此外,网络爬虫还有一些不常用的名称,如蚂蚁、自动索引、模拟程序或蠕虫等。
本教程讲解 Python 与网络爬虫,包括爬虫原理与第一个爬虫程序、使用 Python 爬取图片、使用 Scrapy 框架、模拟浏览器等。
爬虫的设计思路如图1所示:
- 明确需要爬取的网页的URL。
- 通过HTTP请求来获取对应的网页。
-
提取网页中的内容,这里有两种情况:
- 如果是有用的数据,就保存起来;
- 如果需要继续爬取网页,就重新指定步骤2。
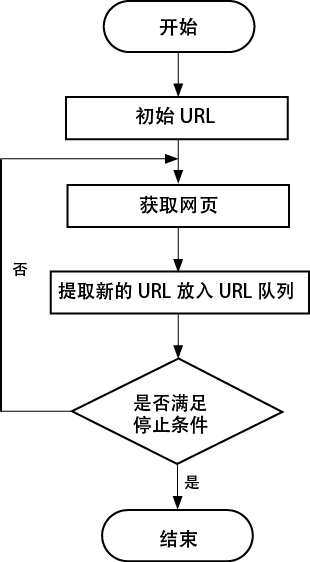
图1:爬虫的设计思路
第一个Python爬虫程序
Python 常使用 requests 模块来模拟浏览器发送请求,获取响应数据。requests 模块属于第三方模块,需要单独安装后才能使用。requests 的安装命令如下所示:
pip install requests
常用的请求方式有两种,分别是 GET 和 POST 请求,对应着 requests.get 和 requests.post 方法。它们的语法如下:
requests.get(url, params=sNone, **kwargs) requests.post(url, data=None, json=None, **kwargs)url 是请求的地址,如果发送 GET 请求,就使用 params 传递参数;如果发送 POST 请求,就使用 data 传递参数。返回值是本次请求对应的响应对象。
范例
这是第一个 Python 爬虫程序的完整示例。
# 导入模块
import requests
# 发送GET请求
r = requests.get('https://httpbin.org/get')
print(r.text)
# 发送POST请求,并传递参数
r = requests.get('https://httpbin.org/get', params={'key1': 'value1', 'key2': 'value2'})
print(r.text)
# 发送POST请求,并传递参数
r = requests.post('https://httpbin.org/post', data={'key': 'value'})
print(r.text)
# 其他HTTP请求类型:PUT、DELETE、HEAD和OPTIONS
r = requests.put('https://httpbin.org/put', data={'key': 'value'})
print(r.text)
r = requests.delete('https://httpbin.org/delete')
print(r.text)
r = requests.head('https://httpbin.org/get')
print(r.text)
r = requests.options('https://httpbin.org/get')
print(r.text)
运行结果:
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.21.0"
},
"origin": "219.156.65.116",
"url": "https://httpbin.org/get"
}
…<省略部分输出>…
{
"args": {},
"data": "",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "0",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.21.0"
},
"json": null,
"origin": "219.156.65.116",
"url": "https://httpbin.org/delete"
}
范例分析
requests 可以很方便地发送各种请求,因为其封装了对应的方法。它常用的是 GET 和 POST 请求,如果需要传递参数,GET 请求使用 params,POST 请求使用 data。requests 得到响应对象r,r.text 表示获取的是解码之后的内容。
如果参数中含有中文,就自动进行 urlencode 编码,不需要使用者再手动实现编码。
使用Python爬取图片
上面讲解了爬虫原理与第一个爬虫程序,下面讲解使用 Python 爬取图片。首先访问 360 图片网站,如图2所示。
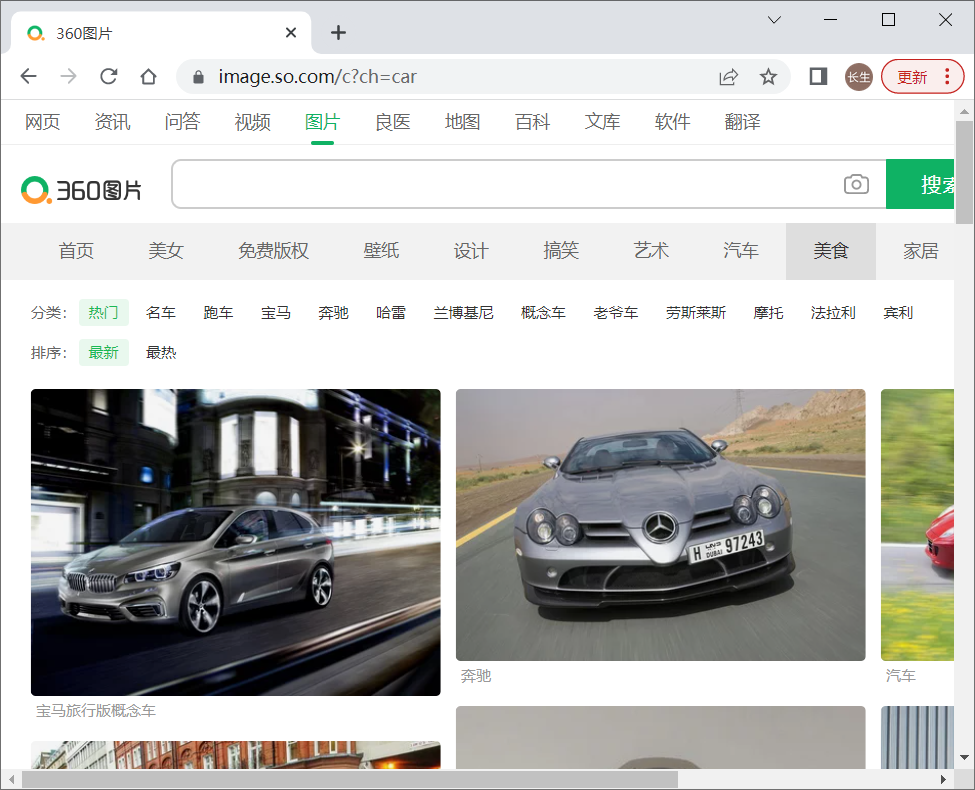
图2:360 图片网站
通过观察可以发现,网页中的图片并没有分页,而是可以通过下拉滚动条自动生成下一页。
通过监听 Network,每次浏览到网页的最后都会多一条请求,仔细观察会发现请求之间是存在一定规律的,如图3所示。
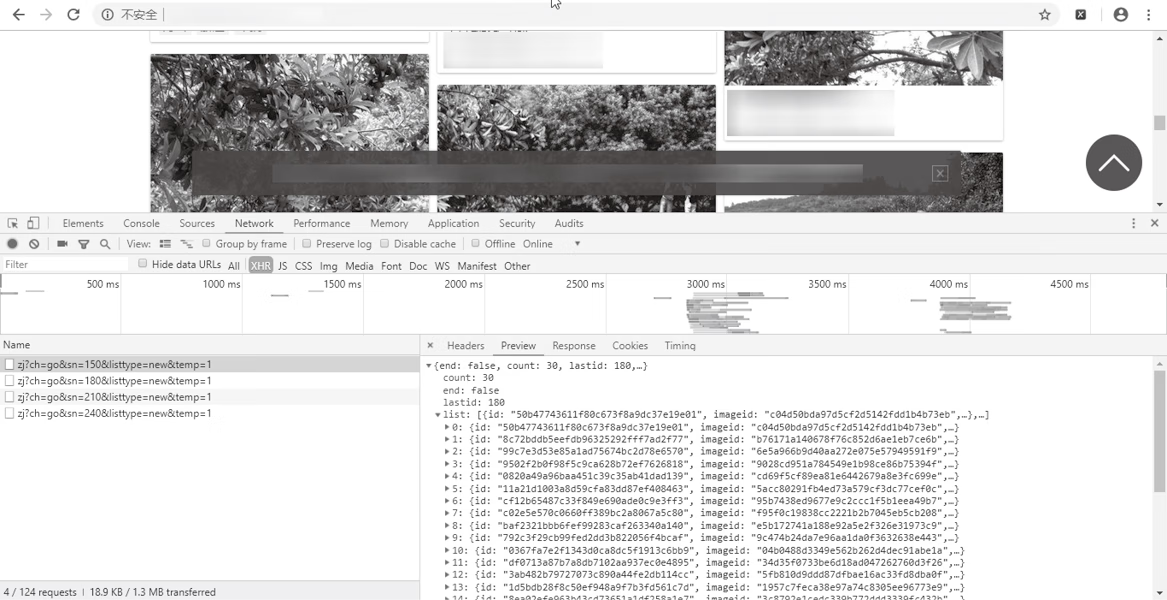
图3:监听
它们都是 http://image.so.com/zj?ch=go&sn={}&listtype=new&temp=1 这样的格式,改变的值只是 sn 中的数字,这就是所需要的页码,可以访问链接进行验证。
现在已经取得所需要的链接,可写出循环的代码,这里以查找前 10 页为例,代码如下所示。
for i in range(10):
url = self.temp_url.format(self.num * 30)
返回的是 JSON 格式的字符串,转成字典,通过键值对获取图片的 URL,然后向这个 URL 发送请求,获取响应字节。将图片返回的响应字节保存到本地。图片的名字不改变。爬取360图片的思路如下:
- 循环准备分页 URL。
- 分别向分页 URL 发送请求,获取响应 JSON 格式的字符串,提取所有的图片 URL。
- 分别向图片 URL 发送请求,获取响应字节,保存到本地。
范例
使用 Python 爬取 360 图片的完整代码。
from retry import retry
import requests
import json
import time
from fake_useragent import UserAgent
class ImgSpider:
def _ _init_ _(self):
"""初始化参数"""
ua = UserAgent()
# 将要访问的url .{}用于接收参数
self.temp_url = "http://image.so.com/zj?ch=go&sn={}&listtype=new&temp=1"
self.headers = {
"User-Agent": ua.random,
"Referer": "http://s.360.cn/0kee/a.html",
"Connection": "keep-alive",
}
self.num = 0
def get_img_list(self, url):
"""获取存放图片URL的集合"""
response = requests.get(url, headers=self.headers)
html_str = response.content.decode()
json_str = json.loads(html_str)
img_str_list = json_str["list"]
img_list = []
for img_object in img_str_list:
img_list.append(img_object["qhimg_url"])
return img_list
def save_img_list(self, img_list):
"""保存图片"""
for img in img_list:
self.save_img(img)
# time.sleep(2)
@retry(tries=3)
def save_img(self, img):
"""对获取的图片URL进行下载并将图片保存到本地"""
content = requests.get(img).content
with open("./data/" + img.split("/")[-1], "wb") as file:
file.write(content)
print(str(self.num) + "保存成功")
self.num += 1
def run(self):
"""实现主要逻辑"""
for i in range(10):
#获取链接
url = self.temp_url.format(self.num * 30)
# 获取数据
img_list = self.get_img_list(url)
# 保存数据
self.save_img_list(img_list)
break
if _ _name_ _ == '_ _main_ _':
img = ImgSpider()
img.run()
运行结果
运行爬虫程序,结果如下所示:
第0张图片保存成功...
第1张图片保存成功...
第2张图片保存成功...
第3张图片保存成功...
第4张图片保存成功...
第5张图片保存成功...
第6张图片保存成功...
第7张图片保存成功...
第8张图片保存成功...
第9张图片保存成功...
第10张图片保存成功...
第11张图片保存成功...
第12张图片保存成功...
第13张图片保存成功...
...<省略以下输出> ...
查看本地图片,如下所示:
t0101bc5934a0f24496.jpg t01388041a45aee56e1.jpg t018790c86e27bc4c01.jpg t01aa63d968ee65a5c3.jpg t01d604c9bce2b18c62.jpg
t0107fb55578a062843.jpg t013b1d241effa05ab6.jpg t0191c8627a98a684a6.jpg t01b4ff750cae438c5a.jpg t01d887dd159577a87e.jpg
t010909cece5f8e9982.jpg t013ca474bc715ae766.jpg t01931f3fede2c6b03a.jpg t01b52f16508adab4bd.jpg t01d8c656a859bcaf5e.jpg
t011c4860a95a36bd17.jpg t014cae84604d1faa82.jpg t019710f488f19a2840.jpg t01c1778a8a1c098def.jpg t01d8f3a130704bb822.jpg
t011ed903a04d9cf633.jpg t014e19b94d67c1a45e.jpg t019830b8a92b05d3a7.jpg t01c3af0dd9ce5fed4f.jpg t01daebb06cc3aa5668.jpg
...<省略以下输出> ...
从结果看,数据已经被成功爬取。
范例分析
分析分页的特点,找到分页的 URL。使用 requests 发送请求,获取 JSON 格式的数据,提取图片 URL。
向图片 URL 发送请求并获取数据,然后将数据保存到本地。
使用Scrapy框架
Scrapy 是一个为了爬取网站数据、提取结构性数据而编写的应用框架。Scrapy 框架可以应用在数据挖掘、信息处理或存储历史数据等一系列的程序中。其最初是为了页面爬取而设计的,但也可以应用于获取 API 所返回的数据或者通用的网络爬虫。
Scrapy 是用纯 Python 实现的一个爬取网站数据、提取结构性数据的应用框架,用途广泛。用户只需要定制开发几个模块就能轻松实现一个爬虫程序,用来爬取网页内容、图片等。
Scrapy 使用 Twisted(其主要对手是 Tornado)异步网络框架来处理网络通信可以加快下载速度,不用自己实现一个框架,并且包含了各种中间件,可以灵活实现各种需求。
Twisted 是用 Python 实现的基于事件驱动的网络引擎框架,Twisted 支持许多常见的传输及应用层协议,包括 TCP、UDP、SSL/TLS、HTTP、IMAP、SSH、IRC、FTP 等。
就像 Python 一样,Twisted 也具有“内置电池”(Batteries-Included)的特点。Twisted 对于其支持的所有协议都带有客户端和服务器的实现,同时附带基于命令行的工具,使得配置和部署产品级的 Twisted 应用框架变得非常方便。
1) 流程介绍
Scrapy 框架如图4所示图中箭头表示。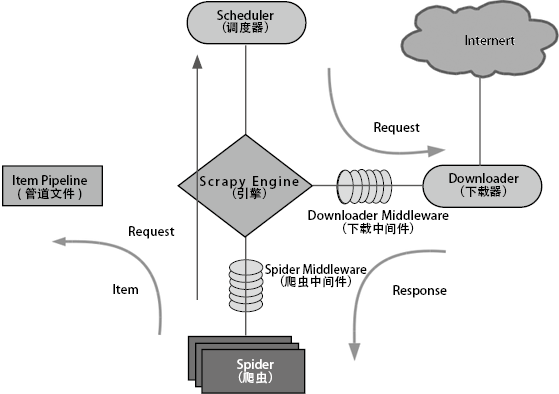
图4:Scrapy 框架
各个模块的介绍如下:
-
Scrapy Engine(引擎)
负责Spider、Item Pipeline、Downloader、Scheduler之间的通信,以及信号、数据的传递等。 -
Scheduler(调度器)
负责接收发送过来的Request(请求),并按照一定的方式进行整理、排列、入队,当Scrapy Engine需要时,再交还给Scrapy Engine。 -
Downloader(下载器)
负责下载Scrapy Engine发送的所有Request,并将其获取到的Response(回应)交还给Scrapy Engine,由Scrapy Engine交给Spider来处理。 -
Spider(爬虫)
负责处理所有Response,分析并从中提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给Scrapy Engine,再次进入Scheduler。 -
Item Pipeline(管道文件)
负责处理Spider中获取到的Item,并进行后期处理(详细分析、过滤、存储等)。 -
Downloader Middleware(下载中间件)
可以被当作一个能自定义扩展下载功能的控制。 -
Spider Middleware(爬虫中间件)
可以理解为一个可以自定义扩展、操作Scrapy Engine和与Spider通信的功能控件(比如进入Spider的Response和从Spider出去的Request)。
Scrapy 的运作流程如下。
代码写好后,开始运行程序:
- Scrapy Engine:Hi!Spider, 你要处理哪一个网站?
- Spider:老大要我处理xxxx.com。
- Scrapy Engine:你把第一个需要处理的URL给我吧。
- Spider:给你,第一个URL是xxxxxxx.com。
- Scrapy Engine:Hi!Scheduler,我这儿有Request,你帮我排序入队一下。
- Scheduler:好的,正在处理,你等一下。
- Scrapy Engine:Hi!Scheduler,把你处理好的Request给我。
- Scheduler:给你,这是我处理好的Request。
- Scrapy Engine:Hi!Downloader,你按照老大的Downloader Middleware的设置帮我下载一下这个Request。
- Downloader:好的!给你,这是下载好的东西。(如果失败:抱歉,这个Request下载失败了。然后Scrapy Engine告诉Scheduler,这个Request下载失败了,你记录一下,我们待会儿再下载。)
- Scrapy Engine:Hi!Spider,这是下载好的东西,并且已经按照老大的Downloader Middleware的设置处理过,你自己处理一下(注意!这些Response默认是交给def parse函数处理的)。
- Spider:(处理完数据之后对于需要跟进的URL),Hi!Scrapy Engine,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
- Scrapy Engine:Hi !Item Pipeline,我这儿有个Item你帮我处理一下!Scheduler!这是需要跟进的URL,你帮我处理一下。然后从步骤(4)开始循环,直到获取完老大需要的全部信息。
- Item Pipeline/Scheduler:好的,现在就做。
注意,只有当 Scheduler 中不存在任何 Request 时,整个程序才会停止(也就是说,对于下载失败的 URL,Scrapy 也会重新下载。)
制作 Scrapy 爬虫一共需要以下4步:
- 新建项目(scrapy startproject xxx):新建一个新的爬虫项目。
- 明确目标(编写 items.py):明确想要爬取的目标。
- 制作爬虫(spiders/xxspider.py):制作爬虫开始爬取网页。
- 存储内容(pipelines.py):设计管道存储爬取内容。
2) 安装 Scrapy
Scrapy的安装命令如下所示。pip install scrapy
3) 创建项目
Scrapy 安装好之后可以开始使用。访问专门供爬虫初学者训练用的网站,如图5所示。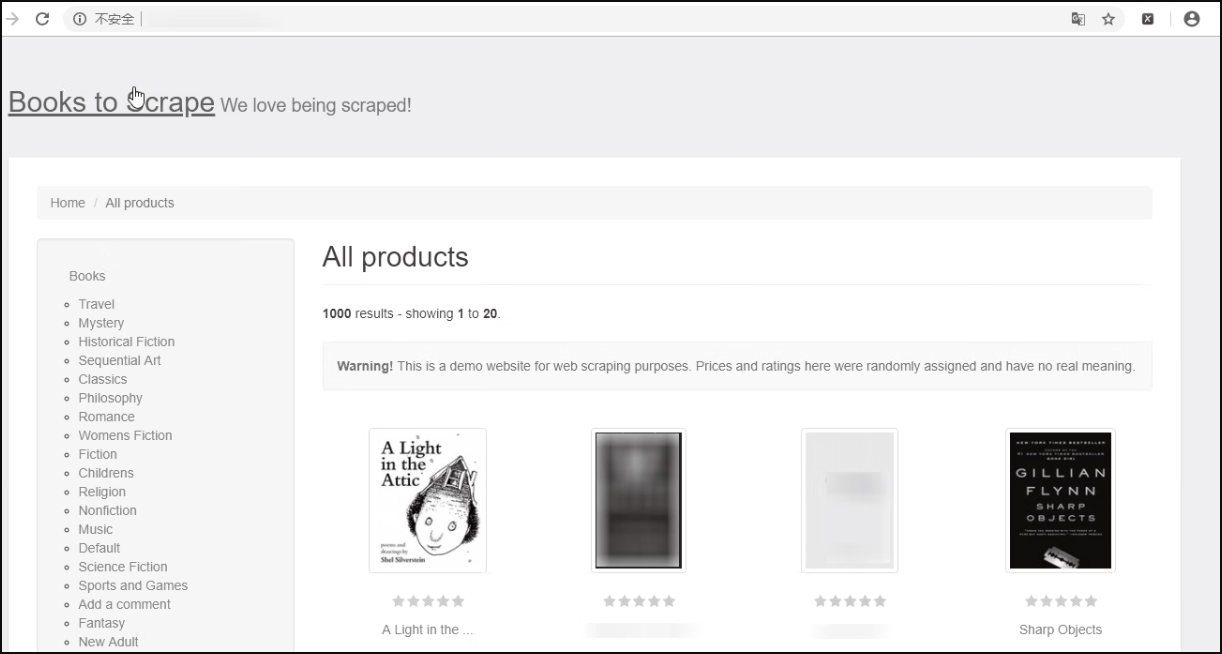
图5:供爬虫初学者训练用的网站
在该网站中,书籍总共有 1000 本,书籍列表页面一共有 50 页,每页有 20 本书的内容,下面仅爬取所有图书的书名、价格和评级。
① 首先,要创建一个 Scrapy 项目,在 Shell 中使用如下命令创建项目,如图6所示。
scrapy startproject spider_01_book

图6:创建项目
② 使用 PyCharm 工具打开项目,如图7所示。
图7:使用 PyCharm 工具打开项目
设置项目的 Python 解释器,使用虚拟环境里的 Python 解释器。
项目中每个文件的说明如下。
- scrapy.cfg:Scrapy 项目的配置文件,其内定义了项目的配置文件路径、部署相关信息等内容。
- items.py:它定义 Item 数据结构,所有的 Item 的定义都可以放在这里。
- pipelines.py:它定义 Item Pipeline 的实现,所有的 Item Pipeline 的实现都可以放在这里。
- settings.py:它定义项目的全局配置。
- middlewares.py:它定义 Spider Middleware 和 Downloader Middleware 的实现。
- spiders:其内包含各 Spider 的实现,每个 Spider 都有一个文件。
4) 分析页面
编写爬虫程序之前,首先需要对要爬取的页面进行分析。主流的浏览器中都带有分析页面的工具或插件,这里选用 Chrome 浏览器的开发者工具分析页面。单本图书的信息如图8所示。

图8:单本图书的信息
在 Chrome 浏览器中访问网站,选中任意一本书,查看其 HTML 代码,如图9所示。
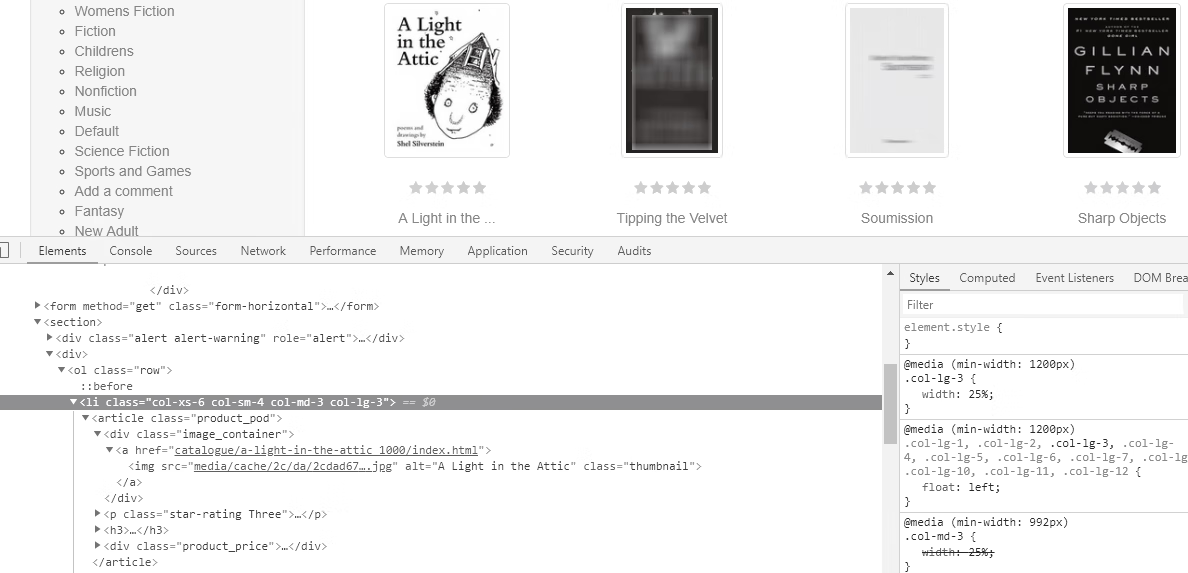
图9:查看 HTML 代码
查看后发现,在 <ol class="row"> 下的 li 中有一个 <article> 标签,这里面存放着该书的所有信息,包括图片、书名、价格和评级:
- 书名为 <a href="catalogue/a-light-in-the-attic_1000/index.html" alt="A Light in the Attic"class="thumbnail">...</a> 中的文字;
- 价格为 <div class="price_color">...</div> 中的文字;
- 评级为 <p class="star-rating Three"> 中的 class 的第二个值 Three。
按照数量算是 20 个 <article> 标签,正好和 20 本的数量对应。
也可以使用 XPath 工具查找,如图10所示。

图10:使用 XPath 工具查找
选中页面下方的【next】按钮并单击鼠标右键,然后查看其 HTML 代码,如图11所示。
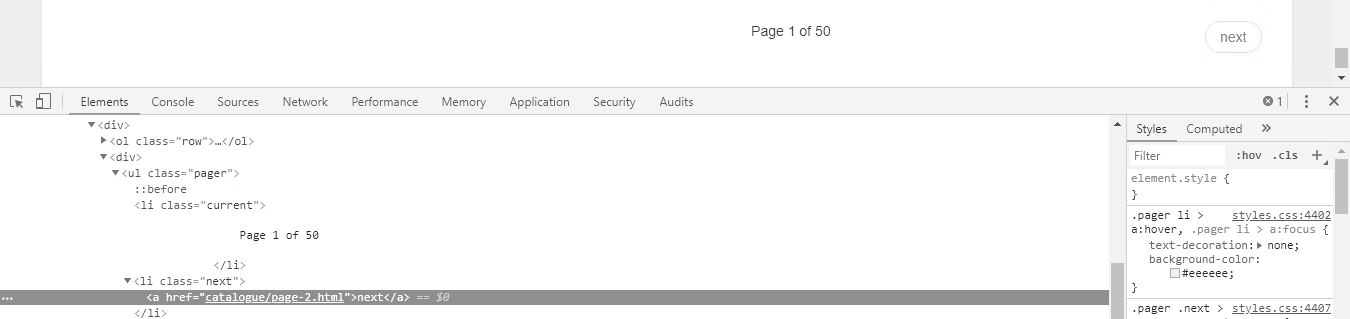
图11:查看【next】按钮的 HTML 代码
在这个被选中的 <a> 标签中,<a href="catalogue/page-2.html">next</a> 中的 href 属性就是要找的 URL,它是一个相对地址,需要拼接 http://books.toscrape.com/ 得到 http://books.toscrape.com/catalogue/page-2.html。
同样,可以测试一下,改变这里的 page-num 的 num,也就是分页的页码,比如 num 可以为 1~50,表示第 1 页 ~ 第 50 页。
5) 创建爬虫类
分析完页面后,接下来编写爬虫程序,进入项目并使用如下命令创建爬虫类,如图12所示。scrapy startproject spider_01_book

图12:创建爬虫类
在 PyCharm 中打开项目,在 spiders 包下已经创建好 bookstoscrape.py 文件。在 Scrapy 中编写一个爬虫程序,即实现一个 scrapy.Spider 的子类,代码如下所示。
# -*- coding: utf-8 -*-
import scrapy
class BookstoscrapeSpider(scrapy.Spider):
name = 'bookstoscrape'
allowed_domains = ['books.toscrape.com']
start_urls = ['http://books.toscrape.com/']
def parse(self, response):
pass
下面修改 bookstoscrape.py 文件,实现爬取功能,代码如下所示。
# -*- coding: utf-8 -*-
import scrapy
class BookstoscrapeSpider(scrapy.Spider):
"""爬虫类,继承Spider"""
# 爬虫的名字——每一个爬虫的唯一标识
name = 'bookstoscrape'
# 允许爬取的域名
allowed_domains = ['books.toscrape.com']
# 初始爬取的URL
start_urls = ['http://books.toscrape.com/']
# 解析下载
def parse(self, response):
# 提取数据
# 每一本书的信息在<article class="product_pod">中,使用
# xpath方法找到所有的article 元素,并依次迭代
for book in response.xpath('//article[@class="product_pod"]'):
# 书名信息在article > h3 > a 元素的title属性里
# 例如:<a title="A Light in the Attic">A Light in the ...</a>
name = book.xpath('./h3/a/@title').extract_first()
# 书价信息在article > div[@class="product_price"] 的文字中
# 例如:<p class="price_color">£51.77</p>
price = book.xpath('./div[2]/p[1]/text()').extract_first()[1:]
# 书的评级在article > p 元素的class属性里
# 例如 :<p class="star-rating Three">
rate = book.xpath('./p/@class').extract_first().split(" ")[1]
# 返回单个图书对象
yield {
'name': name,
'price': price,
'rate': rate,
}
# 提取下一页的URL
# 下一页的URL在li.next > a 里的href属性值
# 例如 :<li class="next"><a href="catalogue/page-2.html">next</a></li>
next_url = response.xpath('//li[@class="next"]/a/@href').extract_first()
# 判断
if next_url:
# 如果找到下一页的URL,得到绝对路径,构造新的Request对象
next_url = response.urljoin(next_url)
# 返回新的Request对象
yield scrapy.Request(next_url, callback=self.parse)
如果上述代码中有看不懂的部分,不必担心,这里只要先对实现一个爬虫程序有整体印象即可。编写的 spider 对象,必须继承自 scrapy.Spider,要有 name,name 是 spider 的名字,还必须要有 start_urls,这是 Scrapy 下载的第一个网页,告诉 Scrapy 爬取工作从这里开始。parse 函数是 Scrapy 默认调用的,它实现爬取逻辑。
下面对 BookstoscrapeSpider 的实现进行简单说明,如表1所示。
| 编号 | 属性 | 描述 |
|---|---|---|
| 1 | name | 一个 Scrapy 项目中可能有多个爬虫,每个爬虫的 name 属性是其自身的唯一标识,在一个项目中不能有同名的爬虫,本例中的爬虫取名为 book stoscrape。 |
| 2 | allowed_ domains | 可选。包含了 Spider 允许爬取的域名列表。当 OffsiteMiddleware 启用时,域名不在列表中的 URL 不会被跟进。 |
| 3 | start urls | 一个爬虫总要从某个(或某些)页面开始爬取,这样的页面称为起始爬取点,start_urls 属性用来设置一个爬虫的起始爬取点。 |
| 4 | parse(response) |
当 response 没有指定回调函数时,该方法是 Scrapy 处理下载的 response 的默认方法。 parse 负责处理 response 并返回处理的数据及(或)跟进的 URL。Spider 对其他的 Request 的回调函数也有相同的要求。 parse 方法及其他的 Request 回调函数必须返回一个包含 Request 及(或)ltem 的可迭代的对象,它的参数为 response ( Response对象)——用于分析的 response。 |
6) 运行爬虫
写完代码后,运行爬虫爬取数据。在 Shell 中执行 scrapy crawl <SPIDER_NAME> 命令运行爬虫 bookstoscrape ,并将爬取的数据存储到一个 CSV 文件中,如下所示。scrapy crawl bookstoscrape -o bookstoscrape.csv
细节说明:- crawl 表示启动爬虫。
- bookstoscrape 是之前在 bookstoscrape.py 中的 BookstoscrapeSpider 中定义的 name。
- -o 表示保存文件的路径,没有这个参数也能启动爬虫,只不过数据没有保存下来而已。
- bookstoscrape.csv 是文件名。
运行结果
Z:\PycharmProjects\book\ch18\18.3\spider_01_book>scrapy crawl bookstoscrape -o bookstoscrape.csv
2020-10-14 14:14:52 [scrapy.utils.log] INFO: Scrapy 2.4.0 started (bot: spider_01_book)
2020-10-14 14:14:52 [scrapy.utils.log] INFO: Versions: lxml 4.5.2.0, libxml2 2.9.5, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 20.3.0, Python 3.7.0 (v3.7.0:1bf9cc
5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)], pyOpenSSL 19.1.0 (OpenSSL 1.1.1h 22 Sep 2020), cryptography 3.1.1, Platform Windows-7-6.1.7601-SP1
2020-10-14 14:14:52 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2020-10-14 14:14:52 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'spider_01_book',
'NEWSPIDER_MODULE': 'spider_01_book.spiders',
'ROBOTSTXT_OBEY': True,
'SPIDER_MODULES': ['spider_01_book.spiders']}
2020-10-14 14:14:52 [scrapy.extensions.telnet] INFO: Telnet Password: 304a52c2fceb08f2
2020-10-14 14:14:52 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.feedexport.FeedExporter',
'scrapy.extensions.logstats.LogStats']
2020-10-14 14:14:52 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2020-10-14 14:14:52 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2020-10-14 14:14:52 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2020-10-14 14:14:52 [scrapy.core.engine] INFO: Spider opened
2020-10-14 14:14:52 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2020-10-14 14:14:52 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2020-10-14 14:14:53 [scrapy.core.engine] DEBUG: Crawled (404) <GET http://books.toscrape.com/robots.txt> (referer: None)
2020-10-14 14:14:53 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://books.toscrape.com/> (referer: None)
2020-10-14 14:14:53 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/>
{'name': 'A Light in the Attic', 'price': '51.77', 'rate': 'Three'}
2020-10-14 14:14:53 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/>
{'name': 'Tipping the Velvet', 'price': '53.74', 'rate': 'One'}
2020-10-14 14:14:53 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/>
{'name': 'Soumission', 'price': '50.10', 'rate': 'One'}
2020-10-14 14:14:53 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/>
{'name': 'Sharp Objects', 'price': '47.82', 'rate': 'Four'}
2020-10-14 14:14:53 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/>
{'name': 'Sapiens: A Brief History of Humankind', 'price': '54.23', 'rate': 'Five'}
2020-10-14 14:14:53 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/>
{'name': 'The Requiem Red', 'price': '22.65', 'rate': 'One'}
2020-10-14 14:14:53 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/>
{'name': 'The Dirty Little Secrets of Getting Your Dream Job', 'price': '33.34', 'rate': 'Four'}
... <省略以下输出> ...
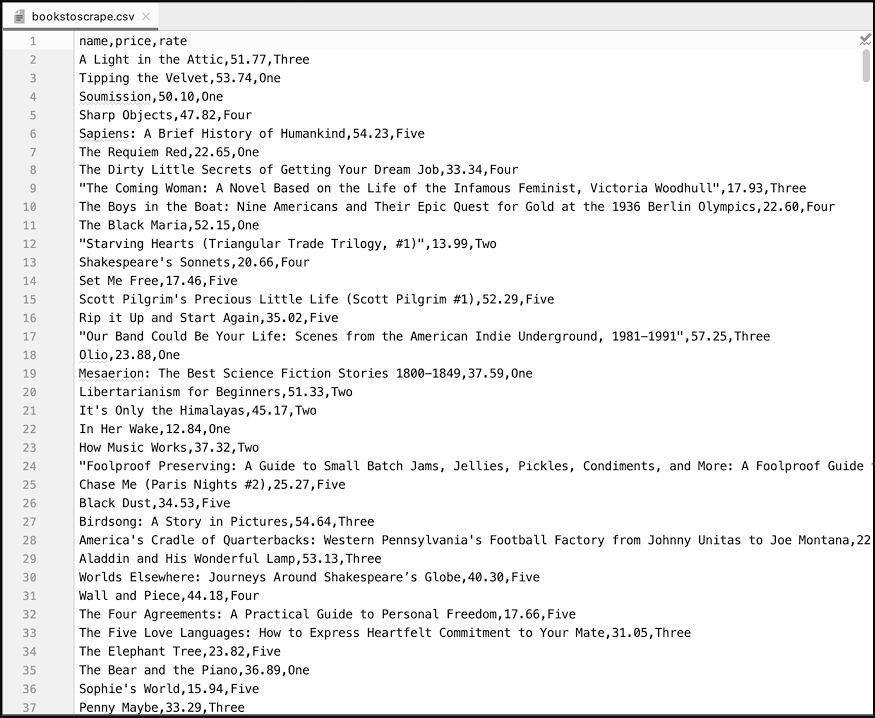
图13:爬取到的数据
从图13所示的数据可以看出,爬虫成功地爬取到了 1000 本书的书名和价格信息等(50 页,每页 20 项)。第一行是 3 个列名。
这里导出的是 CSV 格式的文件,也可以导出 JSON 和 XML 格式的文件,代码如下所示。
scrapy crawl bookstoscrape-o bookstoscrape.jsonlines
scrapy crawl bookstoscrape-o bookstoscrape.xml
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: